

Introduction
Large Language Models (LLMs) like ChatGPT have transformed how organizations process information, assisting with tasks from coding to document and image analysis. Yet their reliance on pre-trained knowledge limits their utility for private organizational data sources. While Retrieval Augmented Generation (RAG), which provides additional documents as reference for the LLM, has emerged as a solution, its shortcomings leave gaps that GraphRAG fills with knowledge graph-powered intelligence.
The Power (and Limits) of Traditional RAG
RAG enhances LLMs by granting access to custom data sources, enabling reference to private or specialized knowledge absent from training data.
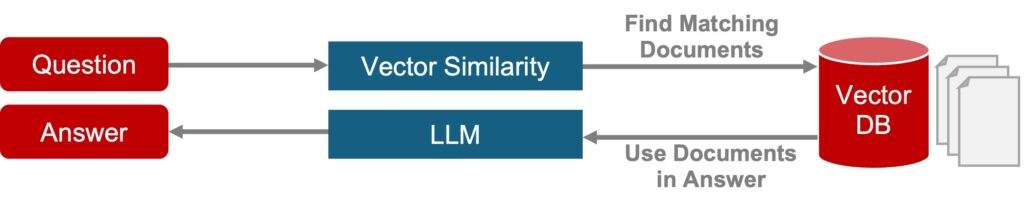
While this works well for many simple use cases, traditional RAG struggles with more complex use cases. Consider a military logistics team querying: “high-risk mechanical issues in desert-operating vehicles.” A RAG system might scan repair logs, parts inventories, and environmental reports, retrieving snippets like:
- “Vehicle #45: transmission overheating”
- “Air filter clogging in sandy conditions”
Yet these results will often:
- Miss patterns: Fail to link multiple “repeated radiator failures” to “prolonged high-temperature deployments” seen across mission logs.
- Overlook systemic risks: Ignore vulnerabilities like a specific engine model failing 40% faster in arid climates.
Without a broader context of what is happening, teams fix symptoms (replacing parts) while missing root causes (preventive redesigns or environmental factors).
Why RAG Falls Short
Traditional RAG’s limitations stem from:
- Fragmented context: Over-reliance on keyword similarity risks retrieving filler text.
- Shallow analysis: Inability to logically map relationships between entities (e.g., environmental stress → mechanical wear).
GraphRAG: Contextual Intelligence via Knowledge Graphs
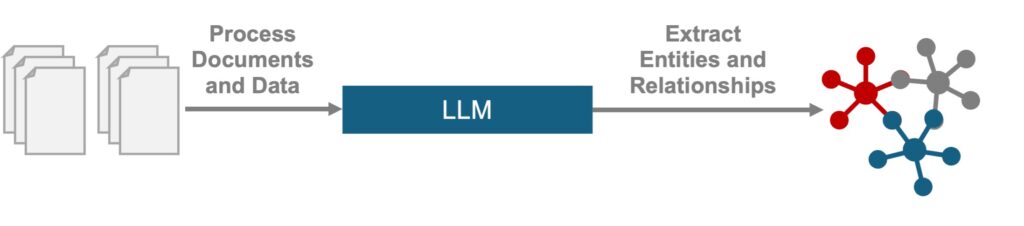
GraphRAG addresses these gaps with knowledge graphs—dynamic networks mapping entities, relationships, and hierarchies. Using knowledge graphs for information retrieval mirrors human reasoning, enabling precise answers to complex operational queries.
How It Works
Going back to our example, we can see how GraphRAG can pick up on insights missed by traditional RAG:
- Graph Construction An LLM extracts entities like armored vehicle models, failure codes, and environmental conditions from maintenance logs, mission reports, and inventories.
- Community Detection Identifies clusters such as engine failures in desert ops or correlated wear patterns in convoy vehicles, creating hierarchical summaries.
- Context-Aware Retrieval For a query like “root causes of transmission failures in high-heat zones,” GraphRAG:
- Pulls from interconnected subgraphs (e.g., linking coolant viscosity to ambient temperature thresholds).
- Surfaces trends like a gearbox model failing 60% faster in 100°F+ environments.
By organizing datasets into semantic clusters, GraphRAG pre-summarizes themes, enabling LLMs to deliver insights anchored in systemic patterns. Traditional RAG answers what broke; GraphRAG explains why it broke and how to prevent it.
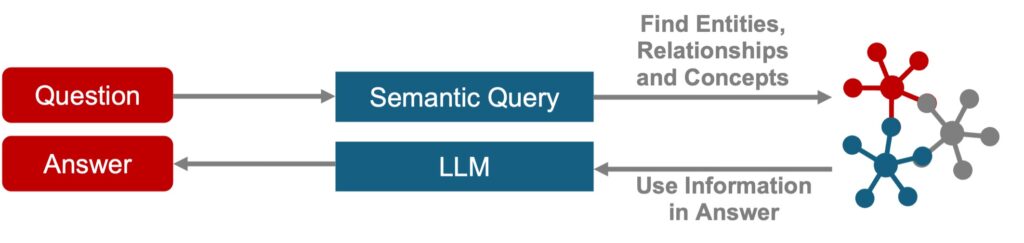
Why Choose GraphRAG?
- Deeper contextualization: Maps relationships (e.g., vehicle failures ↔ environmental stressors), moving beyond keyword matching.
- Reduced hallucinations: Anchors responses to verifiable source material.
- Operational efficiency: Summarizes semantic communities (e.g., desert-operational wear patterns) instead of raw datasets.
At Redhorse, we’ve seen the impact GraphRAG can have for analysis which can be a difference maker for mission-critical decisions. Our years of experience applying graphs to intel and DoD use cases have enabled us to develop a strong analytical foundation that is now enhanced by the addition of LLMs.


